1、背景
GAN作为生成模型的一种新型训练方法,通过discriminative model来指导generative model的训练,并在真实数据中取得了很好的效果。尽管如此,当目标是一个待生成的非连续性序列时,该方法就会表现出其局限性。非连续性序列生成,比如说文本生成,为什么单纯的使用GAN没有取得很好的效果呢?主要的屏障有两点:
1)在GAN中,Generator是通过随机抽样作为开始,然后根据模型的参数进行确定性的转化。通过generative model G的输出,discriminative model D计算的损失值,根据得到的损失梯度去指导generative model G做轻微改变,从而使G产生更加真实的数据。而在文本生成任务中,G通常使用的是LSTM,那么G传递给D的是一堆离散值序列,即每一个LSTM单元的输出经过softmax之后再取argmax或者基于概率采样得到一个具体的单词,那么这使得梯度下架很难处理。
2)GAN只能评估出整个生成序列的score/loss,不能够细化到去评估当前生成token的好坏和对后面生成的影响。
强化学习可以很好的解决上述的两点。再回想一下Policy Gradient的基本思想,即通过reward作为反馈,增加得到reward大的动作出现的概率,减小reward小的动作出现的概率,如果我们有了reward,就可以进行梯度训练,更新参数。如果使用Policy Gradient的算法,当G产生一个单词时,如果我们能够得到一个反馈的Reward,就能通过这个reward来更新G的参数,而不再需要依赖于D的反向传播来更新参数,因此较好的解决了上面所说的第一个屏障。对于第二个屏障,当产生一个单词时,我们可以使用蒙塔卡罗树搜索(Alpho Go也运用了此方法)立即评估当前单词的好坏,而不需要等到整个序列结束再来评价这个单词的好坏。
因此,强化学习和对抗思想的结合,理论上可以解决非连续序列生成的问题,而SeqGAN模型,正是这两种思想碰撞而产生的可用于文本序列生成的模型。
SeqGAN模型的原文地址为:https://arxiv.org/abs/1609.05473,当然在我的github链接中已经把下载好的原文贴进去啦。
结合代码可以更好的理解模型的细节哟:https://github.com/princewen/tensorflow_practice/tree/master/seqgan
2、SeqGAN的原理
SeqGAN的全称是Sequence Generative Adversarial Nets。这里打公式太麻烦了,所以我们用word打好再粘过来,冲这波手打也要给小编一个赞呀,哈哈!
整体流程

模型的示意图如下:
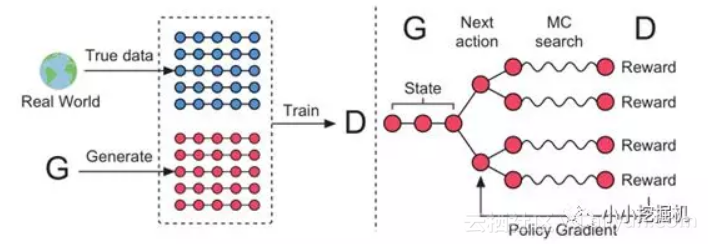
Generator模型和训练
接下来,我们分别来说一下Generator模型和Discriminator模型结构。
Generator一般选择的是循环神经网络结构,RNN,LSTM或者是GRU都可以。对于输入的序列,我们首先得到序列中单词的embedding,然后输入每个cell中,并结合一层全链接隐藏层得到输出每个单词的概率,即:
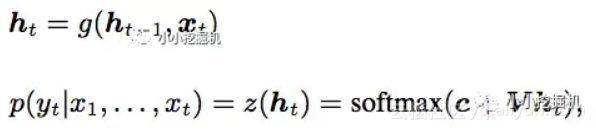
有了这个概率,Generator可以根据它采样一批产生的序列,比如我们生成一个只有,两个单词的序列,总共的单词序列有3个,第一个cell的输出为(0.5,0.5,0.0),第二个cell的输出为(0.1,0.8,0.1),那么Generator产生的序列以0.4的概率是1->2,以0.05的概率是1->1。注意这里Generator产生的序列是概率采样得到的,而不是对每个输出进行argmax得到的固定的值。这和policy gradient的思想是一致的。
在每一个cell我们都能得到一个概率分布,我们基于它选择了一个动作或者说一个单词,如何判定基于这个概率分布得到的单词的还是坏的呢?即我们需要一个reward来左右这个单词被选择的概率。这个reward怎么得到呢,就需要我们的Discriminator以及蒙塔卡罗树搜索方法了。前面提到过Reward的计算依据是最大可能的Discriminator,即尽可能的让Discriminator认为Generator产生的数据为real-world的数据。这里我们设定real-world的数据的label为1,而Generator产生的数据label为0.
如果当前的cell是最后的一个cell,即我们已经得到了一个完整的序列,那么此时很好办,直接把这个序列扔给Discriminator,得到输出为1的概率就可以得到reward值。如果当前的cell不是最后一个cell,即当前的单词不是最后的单词,我们还没有得到一个完整的序列,如何估计当前这个单词的reward呢?我们用到了蒙特卡罗树搜索的方法。即使用前面已经产生的序列,从当前位置的下一个位置开始采样,得到一堆完整的序列。在原文中,采样策略被称为roll-out policy,这个策略也是通过一个神经网络实现,这个神经网络我们可以认为就是我们的Generator。得到采样的序列后,我们把这一堆序列扔给Discriminator,得到一批输出为1的概率,这堆概率的平均值即我们的reward。这部分正如过程示意图中的下面一部分:
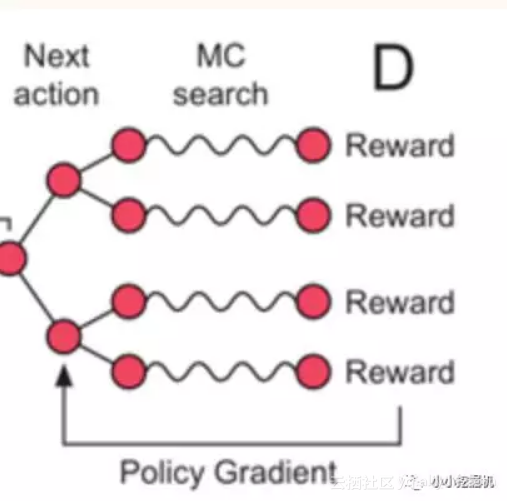
用原文中的公式表示如下:
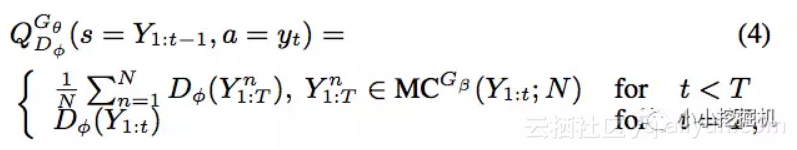
得到了reward,我们训练Generator的方式就很简单了,即通过Policy Gradient的方式进行训练。最简单的思想就是增加reward大的动作的选择概率,减小reward小的动作的选择概率。
Discriminator模型和训练
Discriminator模型即一个分类器,对文本分类的分类器很多,原文采用的是卷积神经网络。同时为了使模型的分类效果更好,在CNN的基础上增加了一个highway network。有关highway network的介绍参考博客:https://blog.csdn.net/l494926429/article/details/51737883,这里就不再细讲啦。
对于Discriminator来说,既然是一个分类器,输出的又是两个类别的概率值,我们很自然的想到使用类似逻辑回归的对数损失函数,没错,论文中也是使用对数损失来训练Discriminator的。
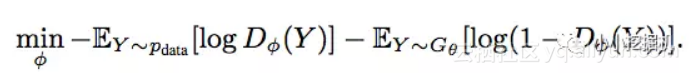
结合oracle模型
可以说,模型我们已经介绍完了,但是在实验部分,论文中引入了一个新的模型中,被称为oracle model。这里的oracle如何翻译,我还真的是不知道,总不能翻译为甲骨文吧。这个oracle model被用来生成真实的序列,可以认为这个model就是一个被训练完美的lstm模型,输出的序列都是real-world数据。论文中使用这个模型的原因有两点:首先是可以用来产生训练数据,另一点是可以用来评价我们Generator的真实表现。原文如下:

我们会在训练过程中不断通过上面的式子来评估我们的Generator与oracle model的相似性。
预训练过程
上面我们讲的其实是在对抗过程中Generator和Discriminator的训练过程,其实在进行对抗之前,我们的Generator和Discriminator都有一个预训练的过程,这能使我们的模型更快的收敛。
对于Generator来说,预训练和对抗过程中使用的损失函数是不一样的,在预训练过程中,Generator使用的是交叉熵损失函数,而在对抗过程中,我们使用的则是Policy Gradient中的损失函数,即对数损失*奖励值。
而对Discriminator来说,两个过程中的损失函数都是一样的,即我们前面介绍的对数损失函数。
SeqGAN模型流程
介绍了这么多,我们再来看一看SeqGAN的流程:

3、SeqGAN代码解析
这里我们用到的代码高度还原了原文中的实验过程,本文参考的github代码地址为:https://github.com/ChenChengKuan/SeqGAN_tensorflow
参考的代码为python2版本的,本文将其稍作修改,改成了python3版本的。其实主要就是print和pickle两个地方。本文代码的github地址为:https://github.com/princewen/tensorflow_practice/tree/master/seqgan
代码实在是太多了,我们这里只介绍一下代码结构,具体的代码细节大家可以参考github进行学习。
3.1 代码结构
本文的代码结构如下:
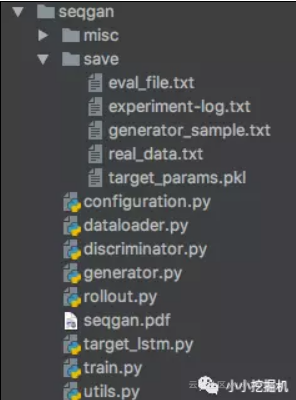
save:save文件夹下保存了我们的实验日志,eval_file是由Generator产生,用来评价Generator和oracle model相似性所产生的数据。real_data是由oracle model产生的real-world数据,generator_sample是由Generator产生的数据,target_params是oracle model的参数,我们直接用里面的参数还原oracle model。
configuration : 一些配置参数
dataloader.py: 产生训练数据,对于Generator来说,我们只在预训练中使用dataloader来得到训练数据,对Discriminator来说,在预训练和对抗过程中都要使用dataloader来得到训练数据。而在eval过程即进行Generator和oracle model相似性判定时,会用刀dataloader来产生数据。
discriminator.py:定义了我们的discriminator
generator.py :定义了我们的generator
rollout.py:计算reward时的采样过程
target_lstm.py:定义了我们的oracle model,这个文件不用管,复制过去就好,哈哈。
train.py : 定义了我们的训练过程,这是我们一会重点讲解的文件
utils.py : 定义了一些在训练过程中的通用过程。
下面,我们就来介绍一下每个文件。
3.2 dataloader
dataloader是我们的数据生成器。
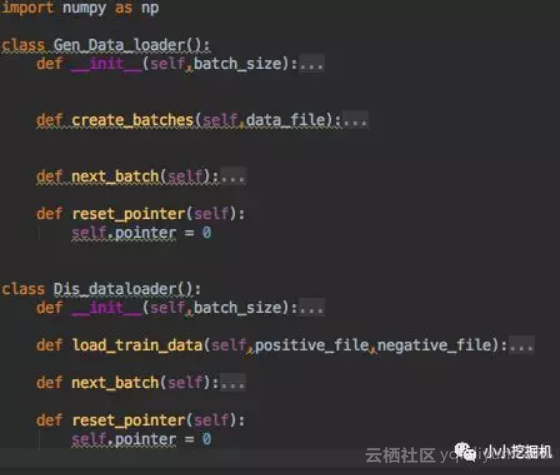
它定义了两个类,一个时Generator的数据生成器,主要用于Generator的预训练以及计算Generator和Oracle model的相似性。另一个时Discriminator的数据生成器,主要用于Discriminator的训练。
3.3 generator
generator中定义了我们的Generator,代码结构如下:
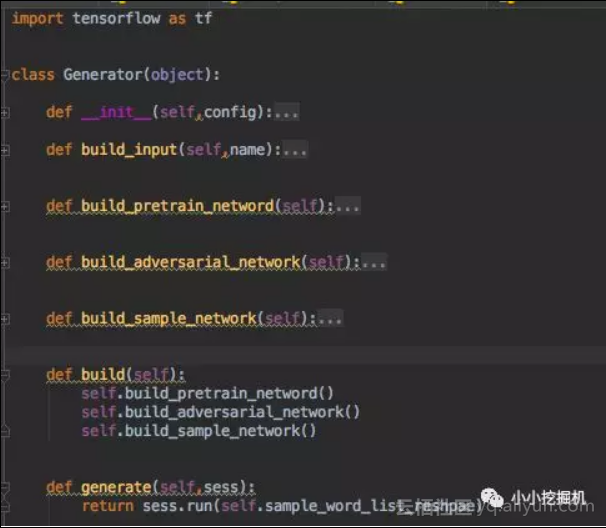
build_input:定义了我们的预训练模型和对抗过程中需要输入的数据
build_pretrain_network : 定义了Generator的预训练过程中的网络结构,其实这个网络结构在预训练,对抗和采样的过程中是一样的,参数共享。预训练过程中定义的损失是交叉熵损失。
build_adversarial_network: 定义了Generator的对抗过程的网络结构,和预训练过程共享参数,因此你可以发现代码基本上是一样的,只不过在对抗过程中的损失函数是policy gradient的损失函数,即 -log(p(xi) * v(xi):
self .pgen_loss_adv = - tf.reduce_sum( tf.one_hot(tf.to_int32(tf.reshape( self .input_seqs_adv,[ -1 ])), self .num_emb,on_value= 1.0 ,off_value= 0.0 ) * tf.log(tf.clip_by_value(tf.reshape( self .softmax_list_reshape,[ -1 , self .num_emb]), 1e-20 , 1.0 )), 1 ) * tf.reshape( self .rewards,[ -1 ])) build_sample_network:定义了我们Generator采样得到生成序列过程的网络结构,与前两个网络参数是共享的。
那么这三个网络是如何使用的呢?pretrain_network就是用来预训练我们的Generator的,这个没有异议。然后在对抗时的每一个epoch,首先用sample_network得到一堆采样的序列samples,然后对采样序列的对每一个时点,使用roll-out-policy结合Discriminator得到reward值。最后,把这些samples和reward值喂给adversarial_network进行参数更新。
3.4 discriminator
discriminator的文件结构如下:
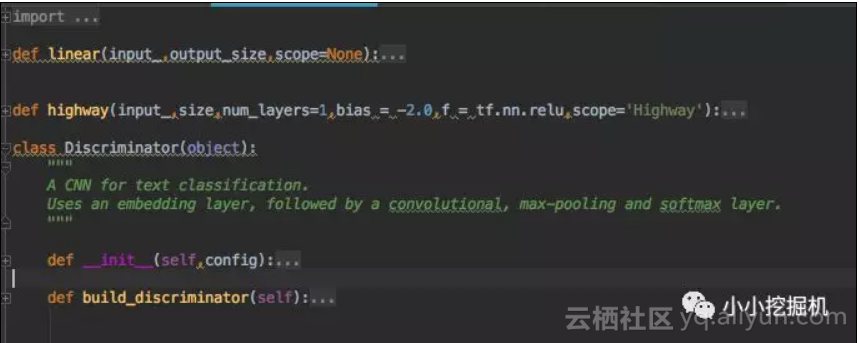
前面的linear和highway函数实现了highway network。
在Discriminator类中,我们采用CNN建立了Discriminator的网络结构,值得注意的是,我们这里采用的损失函数加入了正则项:
with tf.name_scope( "output" ): W = tf.Variable(tf.truncated_normal([num_filters_total, self .num_classes],stddev = 0.1 ),name= "W" ) b = tf.Variable(tf.constant( 0.1 ,shape=[ self .num_classes]),name= 'b' ) self .l2_loss += tf.nn.l2_loss(W) self .l2_loss += tf.nn.l2_loss(b) self .scores = tf.nn.xw_plus_b( self .h_drop,W,b,name= 'scores' ) # batch * num_classes self .ypred_for_auc = tf.nn.softmax( self .scores) self .predictions = tf.argmax( self .scores, 1 ,name= 'predictions' ) with tf.name_scope( "loss" ): losses = tf.nn.softmax_cross_entropy_with_logits(logits= self .scores,labels= self .input_y) self .loss = tf.reduce_mean(losses) + self .l2_reg_lambda + self .l2_loss 3.5 rollout
这个文件实现的通过rollout-policy得到一堆完整序列的过程,前面我们提到过了,rollout-policy实现需要一个神经网络,而我们这里用Generator当作这个神经网络,所以它与前面提到的三个Generator的网络的参数也是共享的。
另外需要注意的是,我们这里要得到每个序列每个时点的采样数据,因此需要进行两层循环:
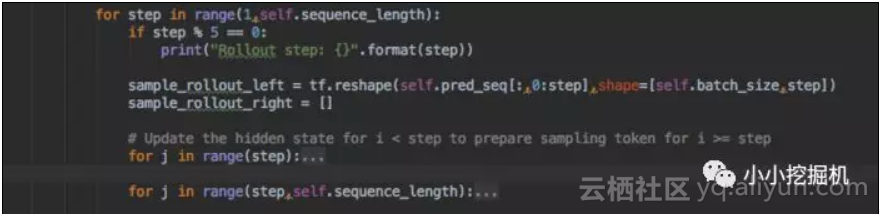
假设我们传过来的序列长度是20,最后一个不需要进行采样,因为已经是完整的序列了。假设当前的step是5,那么0-4是不需要采样的,但我们需要把0-4位置的序列输入到网络中得到state。得到state之后,我们再经过一层循环得到5-19位的采样序列,然后将0-4位置的序列的和5-19位置的序列的进行拼接。
sample_rollout = tf.concat([sample_rollout_left,sample_rollout_right],axis=1)
3.6 utils
utils中定义了两个函数:

generate_samples函数用于调用Generator中的sample_network产生sample或者用于调用target-lstm中的sample_network产生real-world数据
target_loss函数用于计算Generator和oracle model的相似性。
3.7 train
终于改介绍我们的主要流程控制代码了,先深呼吸一口,准备开始!
定义dataloader以及网络
首先,我们获取了configuration中定义的参数,然后基于这些参数,我们得到了三个dataloader。
随后,我们定义了Generator和Discriminator,以及通过读文件来创建了我们的oracle model,在代码中叫target_lstm。
config_train = training_config() config_gen = generator_config() config_dis = discriminator_config() np.random.seed(config_train.seed) assert config_train.start_token == 0 gen_data_loader = Gen_Data_loader(config_gen.gen_batch_size) likelihood_data_loader = Gen_Data_loader(config_gen.gen_batch_size) dis_data_loader = Dis_dataloader(config_dis.dis_batch_size) generator = Generator(config=config_gen) rollout_gen = rollout(config=config_gen) target_params = pickle.load(open( 'save/target_params.pkl' , 'rb' ),encoding= 'iso-8859-1' ) target_lstm = TARGET_LSTM(config=config_gen, params=target_params) # The oracle model discriminator = Discriminator(config=config_dis) discriminator.build_discriminator() 预训练Generator
我们首先定义了预训练过程中Generator的优化器,即通过AdamOptimizer来最小化交叉熵损失,随后我们通过target-lstm网络来产生Generator的训练数据,利用dataloader来读取每一个batch的数据。
同时,每隔一定的步数,我们会计算Generator与target-lstm的相似性(likelihood)
# Build optimizer op for pretraining pretrained_optimizer = tf.train.AdamOptimizer(config_train.gen_learning_rate) var_pretrained = [v for v in tf.trainable_variables() if 'teller' in v.name] gradients, variables = zip( *pretrained_optimizer.compute_gradients(generator.pretrained_loss, var_list=var_pretrained)) gradients, _ = tf.clip_by_global_norm(gradients, config_train.grad_clip) gen_pre_update = pretrained_optimizer.apply_gradients(zip(gradients, variables)) sess.run(tf.global_variables_initializer()) generate_samples(sess,target_lstm,config_train.batch_size,config_train.generated_num,config_train.positive_file) gen_data_loader.create_batches(config_train.positive_file) log = open( 'save/experiment-log.txt' , 'w' ) print ( 'Start pre-training generator....' ) log.write( 'pre-training...\n' ) for epoch in range(config_train.pretrained_epoch_num): gen_data_loader.reset_pointer() for it in range(gen_data_loader.num_batch): batch = gen_data_loader.next_batch() _,g_loss = sess.run([gen_pre_update,generator.pretrained_loss],feed_dict={generator.input_seqs_pre:batch, generator.input_seqs_mask:np.ones_like(batch)}) if epoch % config_train.test_per_epoch == 0 : generate_samples(sess,generator,config_train.batch_size,config_train.generated_num,config_train.eval_file) likelihood_data_loader.create_batches(config_train.eval_file) test_loss = target_loss(sess,target_lstm,likelihood_data_loader) print ( 'pre-train ' ,epoch, ' test_loss ' ,test_loss) buffer = 'epoch:\t' + str(epoch) + '\tnll:\t' + str(test_loss) + '\n' 预训练Discriminator
预训练好Generator之后,我们就可以通过Generator得到一批负样本,并结合target-lstm产生的正样本来预训练我们的Discriminator。
print ( 'Start pre-training discriminator...' ) for t in range(config_train.dis_update_time_pre): print ( "Times: " + str(t)) generate_samples(sess,generator,config_train.batch_size,config_train.generated_num,config_train.negative_file) dis_data_loader.load_train_data(config_train.positive_file,config_train.negative_file) for _ in range(config_train.dis_update_time_pre): dis_data_loader.reset_pointer() for it in range(dis_data_loader.num_batch): x_batch,y_batch = dis_data_loader.next_batch() discriminator.input_x : x_batch, discriminator.input_y : y_batch, discriminator.dropout_keep_prob : config_dis.dis_dropout_keep_prob _ = sess.run(discriminator.train_op,feed_dict) 定义对抗过程中Generator的优化器
这里定义的对抗过程中Generator的优化器即最小化我们前面提到的policy gradient损失,再回顾一遍:
self .pgen_loss_adv = - tf.reduce_sum( tf.one_hot(tf.to_int32(tf.reshape( self .input_seqs_adv,[ -1 ])), self .num_emb,on_value= 1.0 ,off_value= 0.0 ) * tf.log(tf.clip_by_value(tf.reshape( self .softmax_list_reshape,[ -1 , self .num_emb]), 1e-20 , 1.0 )), 1 ) * tf.reshape( self .rewards,[ -1 ]))
# Build optimizer op for adversarial training train_adv_opt = tf.train. AdamOptimizer (config_train.gen_learning_rate) gradients, variables = zip(*train_adv_opt.compute_gradients(generator.gen_loss_adv, var_list=var_pretrained)) gradients, _ = tf.clip_by_global_norm(gradients, config_train.grad_clip) train_adv_update = train_adv_opt.apply_gradients(zip(gradients, variables)) # Initialize global variables of optimizer for adversarial training uninitialized_var = [e for e in tf.global_variables() if e not in tf.trainable_variables()] init_vars_uninit_op = tf.variables_initializer(uninitialized_var) sess.run(init_vars_uninit_op) 对抗过程中训练Generator
对抗过程中训练Generator,我们首先需要通过Generator得到一批序列sample,然后使用roll-out结合Dsicriminator得到每个序列中每个时点的reward,再将reward和sample喂给adversarial_network进行参数更新。
# Start adversarial training for total_batch in range(config_train.total_batch): for iter_gen in range(config_train.gen_update_time): samples = sess.run(generator.sample_word_list_reshpae) feed = { 'pred_seq_rollout:0' :samples } for iter_roll in range(config_train.rollout_num): rollout_list = sess.run(rollout_gen.sample_rollout_step,feed_dict=feed) # np.vstack 它是垂直(按照行顺序)的把数组给堆叠起来。 rollout_list_stack = np.vstack(rollout_list) reward_rollout_seq = sess.run(discriminator.ypred_for_auc,feed_dict={ discriminator. input_x: rollout_list_stack,discriminator. dropout_keep_prob: 1.0 reward_last_tok = sess.run(discriminator.ypred_for_auc,feed_dict={ discriminator. input_x: samples,discriminator. dropout_keep_prob: 1.0 reward_allseq = np.concatenate((reward_rollout_seq,reward_last_tok),axis= 0 )[ : , 1 ] for r in range(config_gen.gen_batch_size): reward_tmp.append(reward_allseq[range(r,config_gen.gen_batch_size * config_gen.sequence_length,config_gen.gen_batch_size)]) reward_rollout.append(np.array(reward_tmp)) rewards = np.sum(reward_rollout,axis = 0 ) / config_train.rollout_num _ ,gen_loss = sess.run([train_adv_update,generator.gen_loss_adv],feed_dict={generator. input_seqs_adv: samples, generator. rewards: rewards}) 对抗过程中训练Discriminator
对抗过程中Discriminator的训练和预训练过程一样,这里就不再赘述。
for _ in range(config_train.dis_update_time_adv): generate_samples(sess,generator,config_train.batch_size,config_train.generated_num,config_train.negative_file) dis_data_loader.load_train_data(config_train.positive_file,config_train.negative_file) for _ in range(config_train.dis_update_time_adv): dis_data_loader.reset_pointer() for it in range(dis_data_loader.num_batch): x_batch,y_batch = dis_data_loader.next_batch() discriminator.input_x:x_batch, discriminator.input_y:y_batch, discriminator.dropout_keep_prob:config_dis.dis_dropout_keep_prob _ = sess.run(discriminator.train_op,feed) 3.8 训练效果
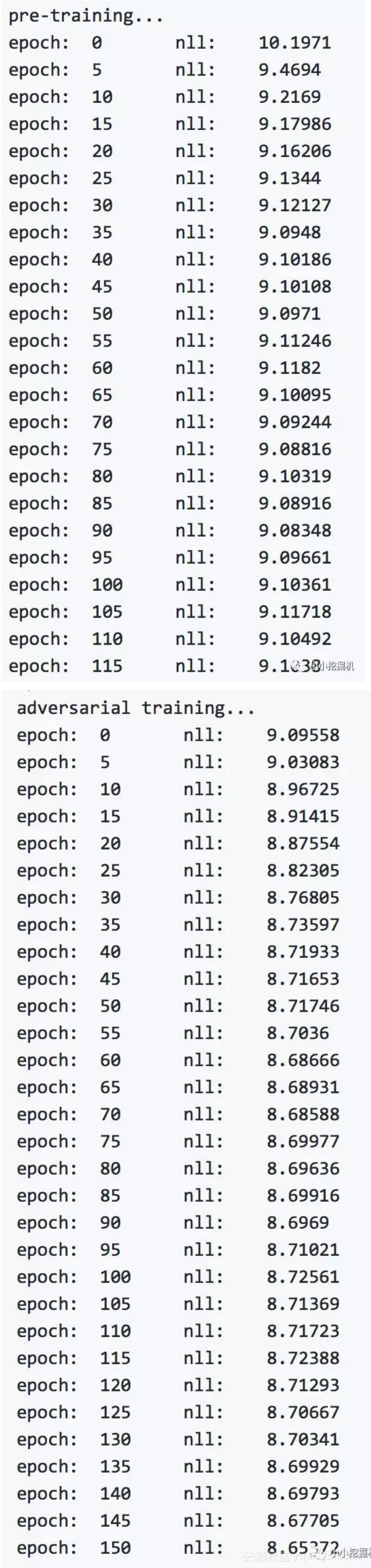
来一发训练效果截图:
原文发布时间为:2018-08-21
本文作者:文文
本文来自云栖社区合作伙伴“”,了解相关信息可以关注“”。